
Table of Contents

In 2019, Capital One, a major financial institution, suffered a data breach that exposed the personal details of over 100 million customers. Incidents like these highlight the increasing importance of safeguarding sensitive information. As our world becomes more digitally interconnected, the challenge of protecting personal and proprietary data intensifies. This lesson dives deep into de-identification as an approach to concealing data specifics, ensuring that even if data is accessed, it remains largely unintelligible. From understanding the “why” behind de-identification to mastering various techniques and their applications, this course prepares you to address today’s data privacy challenges head-on.
As businesses race to leverage the benefits of big data, they also struggle with the ethical and legal responsibilities of handling sensitive information. That’s where you come in. By mastering de-identification, you’ll be equipped with the knowledge to maintain privacy, adhere to regulations, and ensure that data-driven enterprises operate responsibly.
Introduction to De-Identification
De-identification is the process of removing or altering sensitive information such as personal information, patient medical information, intellectual property, business key information, etc, from a database so that the remaining data cannot be easily linked back to individual identities. The primary objective is to ensure privacy while allowing data to be used for research, analysis, or other purposes. It’s a bridge between the need to protect individual privacy and the necessity to utilize data for the greater good.
There are many business reasons and requirements to de-identify these kinds of information, the most commonly seen:
- Regulatory Compliance
- Risk Reduction
- Data Sharing
- Research & Analytics
- Third-party Integrations
- Data Monetization
- Customer Trust
- Reduced Liability
- Cloud Migration
- Training & Development
- Mergers & Acquisitions
- Data Storage Cost Reduction
- International Data Transfers
- Testing Environments
- Public Reporting
There is no argument that we live in an “Information Age” era which revolutionized everything in life. This means that large volumes of data, including personal data, are being collected, stored, and analyzed on an unprecedented scale. We engage in online shopping, use social media platforms, and even access health services online. Every interaction leaves a digital footprint that represents your identity to some extent. By de-identifying ourselves, we are taking a proactive step towards maintaining our privacy. De-identification helps ensure that, even if data is shared or accessed, our personal identity remains protected, and we are less susceptible to threats like identity theft or targeted attacks.
The central dilemma is balancing utility and privacy. On one hand, data drives innovation. It aids research, helps businesses provide better services, and can even lead to societal advancements. On the other hand, there’s a growing concern about how personal data can be misused. By de-identifying data, we are trying to solve this conflict. We are seeking a middle ground where data can still be useful without compromising personal privacy. Furthermore, with increasing legal requirements around the world, such as the General Data Protection Regulation (GDPR) in Europe, de-identification is not just a best practice, but it’s often a legal obligation.
Imagine walking around with your name, address, and other personal details printed on a banner for everyone to see. In the digital space, when our identification is always visible, we are exposed similarly. This constant exposure makes us vulnerable. Hackers can exploit this information for malicious purposes, like fraud or identity theft. Advertisers might use it to intrusively target us. Even benign data collection, when pieced together, can create a detailed profile of an individual, leading to unintended consequences. By always keeping our identification visible, we give away control over our personal narratives and risk our security.
What to De-Identify Precisely?
De-identification often revolves around a sensitive data especially Personally Identifiable Information (PII). While many sources emphasize de-identification for PII, there is nothing stopping using it for military data, business-sensitive information, intellectual property, Protected Health Information (PHI) and in general wherever data privacy is required. However, in this section, we’ll focus on PII due to its prevalent use in various industries.
PII refers to any data that can be used on its own or with other information to identify, contact, or locate a single person, or to identify an individual in context. In the world of cybersecurity and data protection, it’s essential to recognize what qualifies as PII to ensure that such data is handled with extra caution and care.
Here’s a list of common PII elements that organizations and individuals usually aim to de-identify:
- Full name
- Home address
- Email address
- Social security number or national identification number
- Passport number
- Driver’s license number
- Credit card numbers
- Date of birth
- Telephone number
- Personal health information (PHI)
- Bank account numbers
- Biometric records, such as fingerprints or facial recognition data
- Educational records
- Employment history and details
- Digital signatures
- Race or ethnicity
- Religious beliefs
There are many more PII examples, but these are the most common. Understanding and recognizing these pieces of information is the first step towards an effective de-identification strategy. While they may appear benign or routine in some contexts, in the wrong hands, they can be the gateway to personal intrusion and cyber-attacks. Therefore, being aware of PII and ensuring its de-identification becomes important.
It’s essential to recognize the shared characteristics that make these data elements so significant. These commonalities not only underline their importance but also highlight the urgency and responsibility we have in safeguarding them. Here are some key traits:
- Unique Identification as PII elements can uniquely identify a person, making them potentially traceable to an individual. This foundational aspect of PII is what often makes it a prime target for misuse.
- Sensitive Nature as PII elements, like religious beliefs or political affiliations, touch on deeply personal aspects of an individual’s life. Unauthorized disclosure can lead to discrimination, stigma, or even harm.
- High Value for Malicious Intent where information such as bank account numbers have direct financial implications. Even details like a mother’s maiden name can be keys for identity theft or security breaches.
- Regulatory Implications where mishandling of PII can have legal consequences. Many jurisdictions enforce data protection laws that organizations must adhere to.
- Ethical Considerations that go beyond legalities, there’s an ethical responsibility to safeguard such data. Its disclosure can impact an individual’s dignity, autonomy, and overall well-being.
- Universality since these data points, while diverse, are universally recognized as private and personal. Their importance in discussions about cybersecurity and privacy is globally acknowledged.
Important Note: Privacy protection intensifies for specific and unique information. While “John Edward Brian Smith” requires rigorous protection due to its precision, a common first name like “John” is less indicative of a specific individual and might warrant minimal or even no privacy safeguards.
Data Minimization – A Proactive Measure
Before exploring the techniques of de-identifying PII elements, it’s crucial to address the principle of Data Minimization. This is because, at its core, Data Minimization is a proactive approach to data protection. Instead of solely relying on methods to mask or alter data post-collection, this principle advocates for collecting less data from the start. By understanding the essence of Data Minimization, we set the stage for a more comprehensive strategy that includes both proactive (minimizing) and reactive (de-identifying) approaches to data protection.
Data Minimization refers to the principle of collecting, storing, and using only the data that’s necessary for a specific purpose. It’s like packing for a journey with only what you need, leaving behind any excess that could weigh you down or pose risks. In the cybersecurity context, it implies a reduction in the volume of personal data amassed, ensuring that only essential and relevant data points are gathered.
At the intersection of ethical considerations, regulatory compliance, and cybersecurity stands the principle of Data Minimization. As cyber threats evolve and data breaches become more sophisticated, having less data in play reduces potential exposure. This means fewer opportunities for hackers and less damage in case of a security incident. Moreover, with global data protection regulations emphasizing the responsible handling of personal data, Data Minimization is not only a best practice but often a legal requirement.
By adhering to the tenets of Data Minimization, we inherently shield individual privacy. When organizations collect only what they genuinely need, there’s a lower chance of misuse, both intentional (e.g., unauthorized selling of data) and unintentional (e.g., accidental exposure due to a security loophole). Moreover, in the unfortunate event of a data breach, the limited data scope means less personal information is at risk. Thus, Data Minimization acts as the first line of defense in the multilayered approach to data privacy.
You might be wondering why technical controls such as antimalware solutions or firewalls, etc, aren’t enough if they are installed on top of IT systems shielding and preventing cyber attacks.
Well, even though they are essential in any cybersecurity strategy, however, they primarily serve as barriers against external threats. The sheer act of collecting data, even when secured, poses inherent risks. Systems can have vulnerabilities, employees can make errors, and even the most fortified digital walls can be breached. By collecting only necessary data, we reduce the ‘surface area’ vulnerable to attacks. Additionally, as the saying goes, “You can’t lose what you don’t have.” With minimized data, the potential fallout from a breach is also minimized.
While Data Minimization champions collecting less, it doesn’t mean crippling business operations. The key is to understand what’s truly essential. For instance, an online retailer might need a customer’s address for delivery but doesn’t necessarily need their date of birth unless age verification is required. By refining data collection processes, businesses can still operate effectively and efficiently. In many cases, a leaner data approach can even enhance operations by reducing storage costs and streamlining data management.
Data Minimization Elements
At its core, Data Minimization is about balancing operational needs with the imperative to safeguard individual privacy and limit potential risks. In practice, it involves precisely evaluating what data is truly necessary for an operation and refraining from collecting any excess. This not only reduces potential risks but also ensures compliance with data protection regulations. Key to understanding how Data Minimization works in real-life scenarios are the roles involved in data collection and management. Let’s look into three primary terms; Data Subject, Data Controller, and Data Processor.
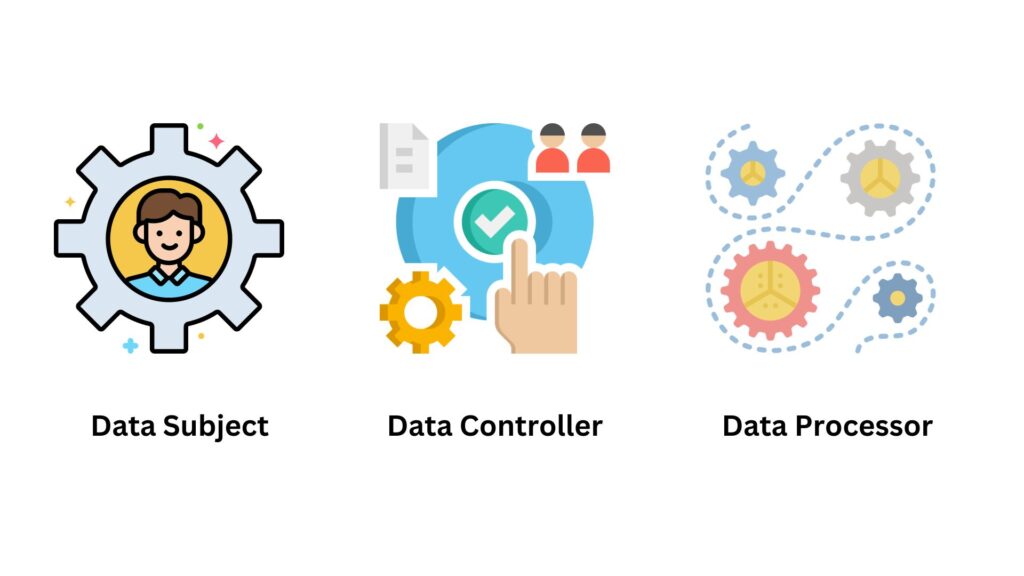
Data Subject
This refers to the individual whom the data is about. In simpler terms, it’s you, me, or anyone whose personal information is being collected. The Data Subject has rights concerning their data, including access to it, the right to correct it, and, in some cases, the right to have it deleted or to object to its processing.
Data Controller
The Data Controller is the entity that determines the purposes and means of processing personal data. Think of it as the decision-maker, the organization, or the person responsible for why and how personal data is processed. They play a central and critical role in ensuring that data collection aligns with the principles of Data Minimization.
Data Processor
While the Data Controller decides the ‘why’ and ‘how’ of data processing, the Data Processor is the entity that processes personal data on behalf of the controller. They might store, analyze, or perform other tasks with the data but always based on the controller’s instructions.
By understanding these roles, we can better appreciate the dynamics of Data Minimization in action. It’s a collective effort, with each entity playing a crucial part in ensuring personal data is handled responsibly and minimally.
How Data Minimization Works in Practice?
Many businesses today rely on massive amounts of data to function effectively. However, the principle of Data Minimization dictates that only the essential pieces of data should be collected and stored. To understand this concept better, let’s break it down with a scenario involving a global recruitment platform, named Acme Corp.
Acme Corp is a global recruitment platform. Concerning data privacy, it takes on the role of a Data Controller. This means Acme Corp determines why they’re collecting certain data (in this case, to match job seekers with potential employers) and how this data will be processed. They make the rules regarding data usage, ensuring compliance with data protection standards and adopting the principle of Data Minimization. Acme Corp, as the Data Controller, derives its data collection practices through a diverse approach. They draft a detailed data collection policy after rigorous internal discussions and case studies analyzing recruitment needs. Additionally, they consult with legal affairs experts to ensure compliance with global data protection regulations. This comprehensive process ensures that their data collection is both efficient for their operational goals and respectful of privacy standards. The end result of Acme Corp’s comprehensive process would typically be a formalized “Data Collection and Privacy Policy” document. This policy would outline the specifics of what data they collect, why they collect it, how it’s used, and the measures in place to protect it. It serves as both an internal guideline for operations and a transparent declaration to users about how their personal information is handled. Acme Corp is obligated to inform users about their Data Collection and Privacy Policy through the Acceptable Use Policy (AUP) which is a common mechanism to inform users about terms and conditions which includes how their data is used and protected, ensuring users are aware and consent to data handling practices.
The individuals who use Acme Corp’s platform in search of employment are the Data Subjects. They provide their personal details to the platform, trusting that their data will be used appropriately and securely. It’s crucial for them to know that only the necessary data to aid their job search is being collected.
Acme Corp doesn’t handle all the data storage and management in-house. Instead, they’ve contracted a cloud service provider for these tasks. This third-party entity, responsible for storing and managing the data as per Acme Corp’s directives, acts as the Data Processor. They don’t decide what to do with the data; they follow the instructions given by Acme Corp. When Acme Corp contracts with a third-party Data Processor, is duty-bound to provide detailed terms, conditions, and policies outlining how the data should be processed. The onus is on Acme Corp to ensure clarity and specificity in these directives. The Data Processor’s responsibility is primarily contingent upon the stipulations set in the contract; they act based on the provided guidelines, and their accountability arises from those contractual terms. The third-party Data Processor is entrusted with specific tasks relating to Acme Corp’s data. Common activities might include:
- Storing data securely in their data centers, safeguarding job seeker profiles.
- Backing up the data periodically.
- Analyzing data for insights or trends, assessing data for insights into hiring patterns.
- Maintaining data integrity and ensuring timely updates, making sure job seeker information is accurate and updated timely.
- Encrypting data for transmission and at rest.
- Correct errors and inconsistencies.
- Transferring data between systems or formats, to ensure seamless operation and enhance user experience.
- Aggregating data for summarized views to provide recruitment trends.
- Manage and control authorized data access to job seekers’ profiles.
- Implementing retention periods and secure deletion protocols.
These Data Processors might operate from different countries, introducing geographical and jurisdictional considerations. Acme Corp’s expectations would typically be twofold; utility in ensuring the data serves its recruitment functions optimally, and security in guaranteeing the data’s confidentiality, integrity, and availability.
Now, with the principles of Data Minimization at the forefront, Acme Corp seeks to collect only the indispensable information from job seekers. Why? By limiting the data they gather, they reduce potential risks and assure the job seekers that their privacy is a top priority.
So, what does Acme Corp collect?
Information such as:
Name: To address and refer to the job seekers.
Contact Information: So potential employers or the platform can reach out.
Qualifications: Essential for matching job seekers with suitable job openings.
What they deliberately avoid collecting are details that don’t aid the recruitment process and could potentially infringe on the job seekers’ privacy, for example:
Height and Weight: These are personal metrics and are usually irrelevant to most job applications.
Marital Status: Personal life details, such as marital status, don’t influence professional qualifications and thus are omitted.
Through this illustration, we see how Acme Corp aligns its operational needs with the principle of Data Minimization, ensuring that the personal information of its users is both protected and used efficiently for its intended purpose; job recruitment.
Quick Quiz
De-Identification Techniques
Our journey in understanding the importance of data privacy and protection has taken us through the domains of de-identification and the prudent act of data minimization. As we looked into data minimization, we recognized its crucial role in being a proactive measure, adeptly addressing half the challenges associated with sensitive personal information. By limiting what is collected at the outset, we’ve curtailed the potential risk of exposure and misuse. Yet, this is only one side of the coin.

Enter the De-Identification Techniques. These are prime practices that tackle the residual challenges, focusing on the personal information that is, out of necessity, still collected. Think of it as a sophisticated safety net for the data that’s essential for business functions but still holds potential privacy implications.
Despite the judicious act of data minimization, there remains information that, while crucial, needs careful handling. This is where the de-identification techniques come into play. These techniques aren’t just about masking or hiding data; they’re about transforming the way we handle, control, and manage sensitive data to ensure its integrity, without compromising its utility.
In this section, we will learn in-depth about these techniques, understanding their mechanisms, benefits, and the scenarios in which they are most effective. By the end, you’ll comprehend how organizations can strike the perfect balance between data utility and privacy, ensuring that while essential data is at hand, the sanctity of personal information remains uncompromised.
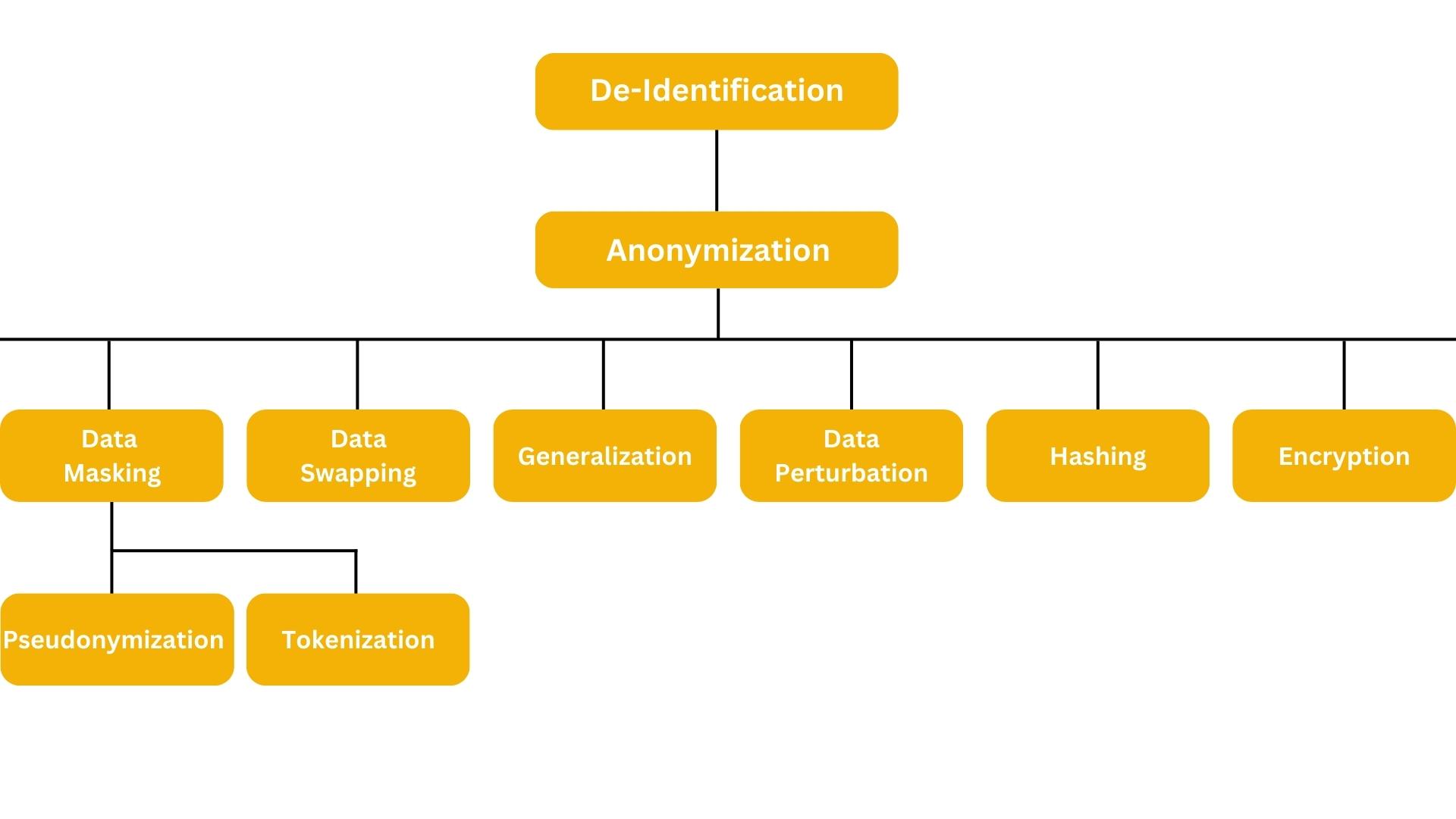
The hierarchy of de-identification techniques can be subjective, and influenced by knowledge and experience. While variations exist, we’ll explore each technique based on the presented structure for clarity and understanding.
Anonymization
Anonymization stands clearly at the forefront of de-identification techniques, serving as the umbrella under which numerous strategies find their place. Why? Its nature lies in rendering data in a manner where individuals cannot be readily identified, thus making it the cornerstone and primary objective of de-identification.
Think of it like the foundation of a building. Just as a building’s strength and stability depend on its foundation, the effectiveness of de-identification rests on the principle of anonymization. Techniques such as data masking, pseudonymization, and others are like the bricks and beams, each serves a purpose and plays a role, but all aim towards the same goal: protecting personal information. This foundational approach ensures that individual identities remain secure at every level.

This broad term is not just a technique, but a concept, an aspiration if you will. Its expansive nature is why everything else nests beneath it; every other method is, in essence, a tool to achieve this larger ambition of anonymization. It’s a bit like aiming for health and using diet, exercise, and sleep as individual tactics. Here, anonymization is the “health” we seek, and the rest are our methods.
In the context of data, where privacy stands significant, the direct relationship between anonymization and de-identification becomes clear. Both aim to shield personal identities and ensure that data, even if accessed unintentionally or maliciously, won’t reveal the individuals behind it. Hence, when we look into the world of de-identification, starting with anonymization is similar to beginning a story from its thematic heart, ensuring a cohesive understanding of all that follows.
Data Masking
Data Masking is a strategic approach within the broad umbrella of anonymization. It specifically aims to hide original data with modified content (characters or other data), but still structurally similar to the original data. This ensures that the data remains usable but doesn’t disclose identifiable information or sensitive data. Given its protective nature, it aligns perfectly with the core principle of anonymization; concealment of identifiable characteristics.



Today, where massive data transactions occur every second, a slight leak of sensitive data can spell monumental disaster, both in terms of reputation and potential legal consequences. For instance, a bank might need to share transaction data with a third-party analytics firm for fraud detection. Using data masking, the bank can modify account numbers while retaining the transaction pattern. Similarly, a healthcare provider sharing patient data for research could mask personal details, ensuring only health metrics are visible. In both cases, data remains functional but stripped of personally identifiable markers. This balance ensures that organizations can still derive value from data, foster collaborations, and enter new markets, all while upholding the trust of their customers and regulatory compliance.
But here’s where it gets complicated. Data masking isn’t a one-size-fits-all strategy. It branches out into specific methods to serve different use cases or data types, leading to sub-techniques. Two of the most popular ones are Pseudonymization and Tokenization which we will talk about them in the next section.
Pseudonymization
Pseudonymization is a data protection technique where identifiable information fields are replaced with artificial identifiers or pseudonyms (Alias). Its core purpose is to render data less identifiable, ensuring that data can’t be attributed to a specific individual without additional information kept separately. This is very important for businesses that require data processing without exposing sensitive personal details, such as research institutions studying trends without revealing individual profiles.
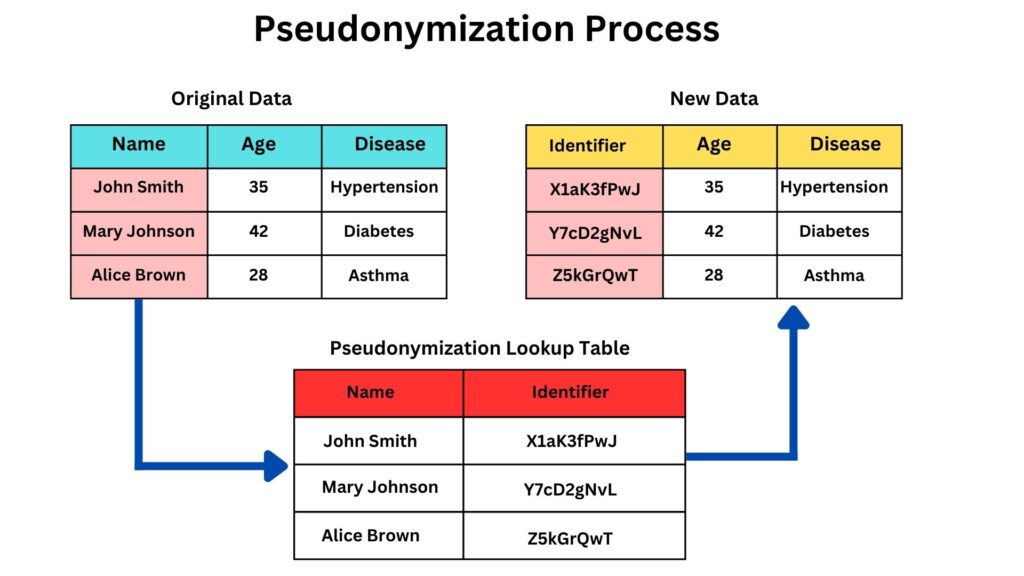
A typical business case might involve a hospital sharing patient records for medical research. The patient’s name, “Jane Smith”, could be transformed into “Patient12345”. By doing so, researchers can analyze health trends without immediately knowing who the individuals are. The effectiveness of pseudonymization largely depends on how it’s implemented. If pseudonyms are robust and there’s a rigorous separation between them and the original data, the security level is high. However, it’s reversible; with the right mapping, one can revert the pseudonyms to the original data. This duality is both its strength and its vulnerability. Pseudonymization utilizes a lookup table, maintaining a structured reference between original values and their respective pseudonyms. This table facilitates reversibility, allowing data to be restored to its initial form. While this offers flexibility in data handling, it also introduces a potential vulnerability if unauthorized access to the table occurs.
In real-world enterprise scenarios, the lookup table is typically stored in a secure database, often separate from the main operational databases to minimize risk. Ensuring maximum security. Best practices dictate that this database is encrypted at rest, undergoes regular vulnerability assessments, and is protected by multi-factor authentication and strict access controls. Ideally, it should be isolated from public-facing interfaces and frequently backed up to secure locations. It should be well monitored to detect and prevent unauthorized access attempts. If breached, the integrity of the entire pseudonymization process is compromised.
Pseudonymization is particularly appropriate for data types with direct identifiers, like names or addresses. It aligns well with vast datasets, especially when automated tools are employed. However, there’s always a risk of data linkage, especially if someone accesses the separate key that links pseudonyms to original identifiers.
Below is an illustrative table on pseudonymization, highlighting the transformation of specific data types for business-driven privacy reasons. This process maintains a reversible link between original and modified data.
| # | Data | Before Change | After Change | Justification |
|---|---|---|---|---|
| 1 | Employee Name | John Doe | PD1234 | Protect employee identity during performance analysis. |
| 2 | Customer Email | johndoe@email.com | PD5678 | Maintain customer privacy in marketing analytics |
| 3 | Patient Health Records | John Doe: Type 2 Diabetes | PD9101: Type 2 Diabetes | Secure patient info while analyzing health trends |
| 4 | User Login | JohnDoe_1990 | PD1121 | Ensure user anonymity in app usage statistics |
| 5 | Client Physical Address | 123 Anystreet, Anytown | PD1314 | Retain client privacy in geographic sales analysis |
When companies use pseudonymization, the key advantage is the potential to DE-ASSOCIATE the data from specific individuals while retaining a method to reconnect it [IF NECESSARY]. After a third party completes their analysis, the company might retain the pseudonym mapping for several reasons:
– Auditability and Accountability
– Further Analysis
– Data Corrections
– Regulatory or Contractual Obligations
However, over time, if the data’s utility diminishes, it’s prudent to discard mappings to minimize risks.
Tokenization
Tokenization emerges as a unique and strategic approach to data protection. It involves substituting sensitive data with non-sensitive placeholders, referred to as “tokens”. A token is a replacement value representing sensitive data. Technically, it’s a unique identifier, often randomly generated, that has no meaningful value or direct link to the original data it replaces, ensuring data security.
The tokenization technique primarily aims to protect data, especially in scenarios where PII or financial data is transferred across systems, like during credit card transactions. Where exposure risks are high. Imagine making an online purchase; instead of transmitting your actual credit card number through various systems, each a potential point of vulnerability, instead of the original data, a tokenized version is sent. So, when you enter “1234-5678-9101-1121” on a website, the payment system might only see and process a token like “ABCD-EFGH-IJKL-MNOP.” The actual mapping, where “1234-5678-9101-1121” equates to “ABCD-EFGH-IJKL-MNOP,” is stored securely in a Token Vault. This ensures that even if a hacker intercepts the transaction data, they only get a meaningless token, leaving your real credit card details uncompromised. The Token Vualt is a secure, centralized database where original data elements and their corresponding tokens are stored. This vault maintains the relationship between real data values and tokens, enabling secure retrieval or de-tokenization when necessary. The token vault’s security is crucial as it holds the keys to revert sensitive tokens back to their original values.
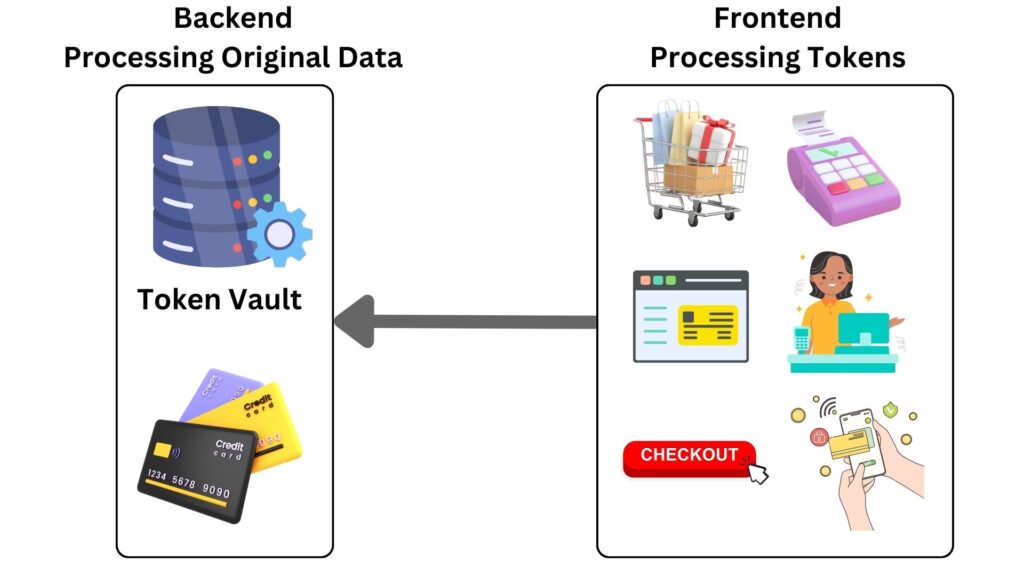
Sensitive data, whether financial, personal identifiable, or military in nature, often traverses multiple systems within an organization’s infrastructure or it could go even beyond depending on the network hybrid. Each of these systems represents a potential point of vulnerability, be it from software flaws, misconfigurations, or human errors. Any piece of sensitive information that might become a lucrative target for unauthorized entities can and should be protected using techniques like tokenization. This ensures that, even if a breach occurs, the exposed data remains non-revealing and the potential damage is significantly minimized.
A good question would be, if an attacker somehow compromised one of the systems and gathered the token values, can’t he query the Token Vault and get a response with the original value?
It’s a valid concern. Ideally, the Token Vault should have strict access controls in place. Just possessing a token doesn’t grant access to the vault. Authorization protocols, multi-factor authentication, and network segmentation are often employed to ensure only legitimate system requests can retrieve the original values. Attackers, despite having tokens, would face significant barriers trying to illicitly access the associated original data from the vault. These barriers not only make unauthorized access extremely challenging but also introduce delays, giving security teams time to detect anomalies and respond effectively, thereby minimizing potential damage and safeguarding the sensitive data contained within the Token Vault.
If the security team observed that there is an active attack on these systems, or the tokens have been breached, what actions can they take?
The security team can replace or rotate token values, similar to changing passwords. However, the ease of this process depends on the tokenization solution and the environment’s complexity. For instance, consider a retail company using tokenization for credit card transactions. If they suspect a breach, they could initiate a token refresh, creating new tokens for all stored credit card numbers. While the old tokens become useless to potential attackers, all point-of-sale systems, billing systems, and other linked platforms must recognize and work with these new tokens, ensuring no business disruption. This transition requires coordination, testing, and might be time-consuming, but it’s a potent countermeasure against a perceived threat.
From a business perspective, tokenization is an attractive proposition. Companies dealing with financial transactions, healthcare records, military national information, or other sensitive data find tokenization especially advantageous. It reduces the scope of compliance audits because actual sensitive data isn’t stored or processed, saving both time and money.
Note that Tokenization is a reversible process, but only when matched with the specific token from the token vault. Without this specific token, the original data remains inaccessible (as we explained earlier), ensuring that even if attackers obtain tokens, they cannot derive the original sensitive information without access to the secure vault’s specific mapping. Therefore, it delivers a substantial security measure as the risk of identifying the original data is minimal, especially since there is no algorithm placed in the process. Yet, the token vault remains a point of concern and needs advanced protection.
Tokenization Process and Architecture
Let’s understand the process and architecture of data Tokenization through a practical example. Assume “Global Brews”, an international coffee shop chain, the Frappuccino recipe is a highly-guarded trade secret. It’s a meticulous blend of specific ratios; coffee beans, milk, sugar, syrups, and ingredients that give it a signature taste. We assume a new branch opens, the training software retrieves the prized Frappuccino recipe from the central database. Instead of these training systems directly accessing the actual recipe, the system uses tokenization for security.
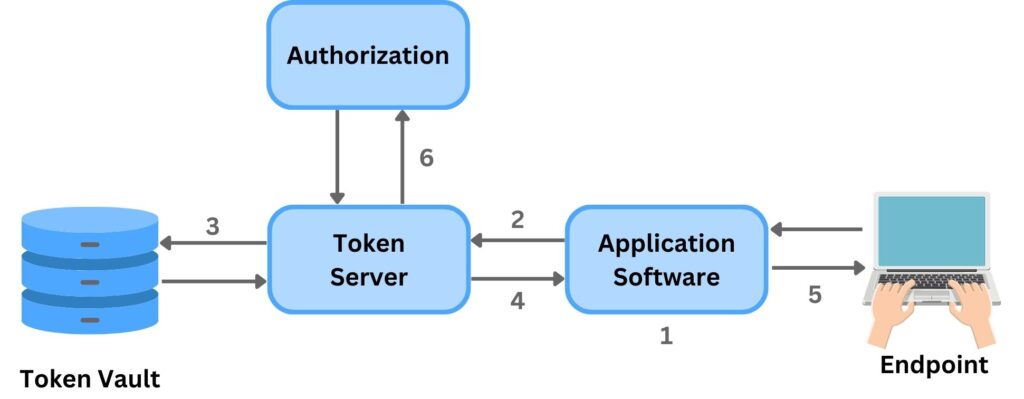
Explore the process with the following steps:
Step 1 – Collecting Original Data: When a new branch of “Global Brews” opens, the training software installed on endpoint systems will retrieve the precious Frappuccino recipe from the central database or repository, where all standardized recipes are stored, to use it to train the staff in a workshop.
Step 2 – Directing to Token Server: Instead of storing this recipe directly on training systems, the software directs it to a tokenization server to generate a token acts as its placeholder in less secure environments like the training systems.
Step 3 – Token Generation: This server, understanding the value of the recipe, generates a unique token that represents this information. The token and the corresponding recipe data is mapped and stored in the Token Database (Vault) securely.
Step 4 – Token Return: The token, a seemingly random string, is then sent back to the training systems software located at the new coffee shop branch.
Step 5 – Token Storage: The branch’s software system stores this token, ensuring the actual recipe remains undisclosed in its local databases.
Step 6 – Data Retrieval: Whenever the recipe is required, the authorized application or user requests the tokenization server to decode the token, revealing the secret recipe for use.
The purpose of the tokenization process in this scenario is to safeguard the sensitive recipe from potential breaches or unauthorized access during Storage and Transit. While the recipe might be viewed temporarily on an endpoint system during training, the actual data isn’t stored there long-term. By using tokenization:
- The training systems do not store the actual sensitive recipe, only tokens. This reduces risk in case of local breaches.
- As the recipe data travels from the central repository to branch locations, it remains tokenized, protecting it from potential interceptions during transmission.
- Only authorized personnel can request the de-tokenization and view the actual recipe. If anyone tries to access the recipe directly the branch’s systems, they’d just find a meaningless token.
Important Note: if an attacker successfully compromises the training systems during the time the recipe is being displayed, they could potentially access the recipe in its clear, untokenized form. This is a vulnerability window during which the sensitive information is at risk. The key advantage of tokenization (or similar measures) is that the sensitive data is in clear form for as minimal a duration and in as few locations as possible, thus reducing the exposure risk. However, it’s essential to have other security measures in place, such as endpoint protection, network security, and real-time monitoring, to guard against such intrusions during these vulnerable periods.
Examine the table below to understand tokenization, a process that replaces sensitive data with non-sensitive placeholders. These tokens, unlike pseudonyms, lack innate meaning and are securely stored.
| # | Dara | Before Change | After Chanage | Justification |
|---|---|---|---|---|
| 1 | Credit Card Number | 1234-5678-9101-1121 | TK0012-3456 | Protect financial data during transactions |
| 2 | Bank Account Number | 5566778899 | TK0001-7890 | Ensure financial data security in banking operations |
| 3 | SSN | 123-45-6789 | TK1122-3344 | Safeguard individual identity in HR processing |
| 4 | Loyalty Card Number | LYT123456789 | TK5678-9101 | Protect customer loyalty data in retail operations |
| 5 | License Plate | ABC-1234 | TK1213-1415 | Anonymize vehicle data in traffic analysis |
Before moving forward with the next technique, let us quickly summarize both Pseudonymization and Tokenization
Pseudonymization
A technique where identifiable data is replaced with unique identifiers or pseudonyms (Alias). It enables organizations to process and analyze data without directly exposing the underlying personal information. It’s particularly useful in business analysis, research, and data sharing, where data insights are required but individual identities are irrelevant or need protection.
Tokenization
Substitution of sensitive data with non-sensitive tokens. The main use case is to safeguard sensitive information and personal identifiable information by replacing them with unique tokens, ensuring that even if exposed systems are compromised, actual information details remain protected within a secure token vault.

A question might come across regarding the common practice on websites where credit card numbers are displayed as “**** **** **** 1234“. At first glance, this appears to be a classic example of data masking, and indeed, it is. However, it’s worth noting that this representation doesn’t inherently signify the use of pseudonymization or tokenization techniques behind the scenes. This visual representation is primarily for user assurance and familiarity. While the full credit card number may be tokenized or pseudonymized in the backend for security reasons, the displayed format is simply a surface-level mask (user frontend) to protect sensitive data from casual observation.
A website can display credit card numbers as masked for user visibility, doesn’t necessarily imply the use of Pseudonymization or Tokenization techniques on the backend. This is merely a visual representation for end-users.
FYI, there are some other sub-techniques fall under Data Masking where the objective is obscuring original values, such as; Static Data Masking (SDM), Dynamic Data Masking (DDM), Redaction, Randomization, Scrambling. However, we are excluding them from this lesson.
Data Swapping
In the expansive field of data de-identification, data swapping emerges as a unique approach, where values between records are exchanged or “swapped”. Data Swapping is typically used in datasets.
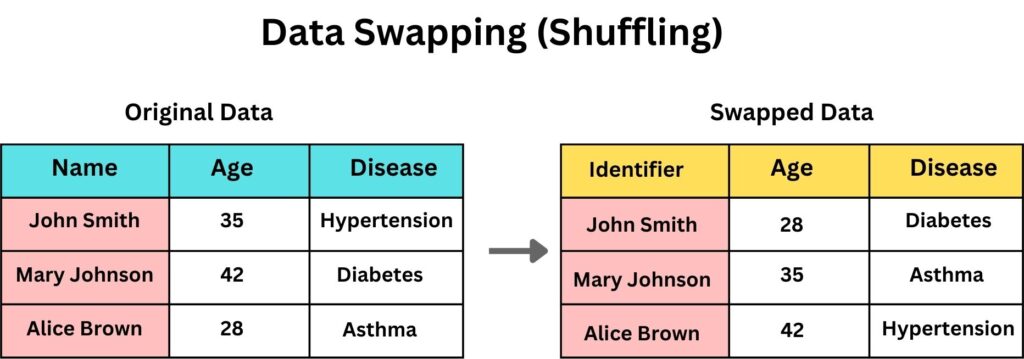
Think of a dataset as a collection of related information organized in rows and columns, much like a spreadsheet or table.
For instance, in a dataset of patients where the ages and ailments are listed; patient A and patient B were initially listed as “25 years with flu” and “40 years with Strep Throat” respectively, might become “40 years with flu” and “25 years with Strep Throat” after swapping. This way, swapping can prevent pinpointing an individual’s ailment based on their age, but researchers can still derive meaningful insights about disease prevalence across age groups, but how?
The core idea behind data swapping is to maintain the overall distribution of data in the dataset while reducing the risk of identifying specific individuals. When done correctly, the dataset after swapping should still retain the statistical properties of the original data.
For example, the overall distribution of a specific attribute (e.g., Flu, age, nationality) remains consistent. So, if 1,000 people have the Flu before swapping, there will still be 1,000 people with the Flu after swapping, and the same applies to the other data that could be swapped. So, when researchers study the dataset to understand, say, the prevalence of flu in different age groups, the results should be statistically similar to analyzing the original, unswapped dataset. The difference is that the specific details of individual records may have changed, making it harder to identify any one person’s exact information. This helps maintain statistical integrity while enhancing privacy. The risk is reduced for an attacker trying to determine a specific individual’s ailment based on their age.
Note that, Data Swapping doesn’t obscure the data unlike Data Masking but it swaps it between records. This means that the swapped data still holds meaningful and authentic value, just not in its original context. The original data exists within the dataset, but its association is shifted to protect the identities or specific details of the subjects.
Let us take examples showcasing how Data Swapping benefits different industries:
Patient’s age and diagnosis; to prevent identification of a specific patient’s ailment but still understand age-related disease prevalence.
Customer’s income bracket and loan amount; to analyze loan distribution across income groups without revealing individual financial situations.
Customer’s purchase category (e.g., electronics, groceries) and loyalty points earned; to study purchasing patterns and loyalty program effectiveness without tracing back to specific buyers.
Student’s grades and extracurricular activities; to understand the relationship between academic performance and extracurricular involvement without pinpointing individual students.
Property size and sale price; to evaluate market trends and property value distribution without disclosing exact property details.
It is worth mentioning that Data swapping’s irreversibility stems from the process itself: individual data attributes are exchanged between records, effectively jumbling the original dataset. This means that after swapping, a specific piece of data no longer correlates directly with its original record. Without knowing the exact algorithm and the precise parameters used for swapping, retracing these changes to obtain the original dataset becomes a labyrinthine challenge. The more data points you swap, the greater the complexity of the data’s original order. This inherent complexity elevates the security level since even if attackers obtain the swapped dataset, deducing the genuine, original information is near-impossible without the specific swapping details.
The swapping process poses a risk of data linkage, especially if an adversary has partial auxiliary information, even though it is minimal but possible. They might deduce relationships between swapped values, attempting to re-link swapped data to its original source, compromising intended de-identification measures.
Data Generalization
Our next de-identification technique is Data Generalization involves replacing detailed data with more general or broader categories. Its primary aim is to reduce the granularity of data, making it harder to identify specific individuals while preserving the dataset’s overall utility. When properly applied, makes data restoration to its precise original form impossible.

Note: each de-identification technique solves the same problem aiming to protect individual privacy and data security but using different approaches suited to various use cases, datasets, and specific requirements,
Imagine a dataset with birth dates. Instead of specifying “April 5, 1990,” generalization might replace it with “1990” or even “1980-1990.” Such adjustments mean the data remains useful for activities like trend analysis, resource allocation, and market segmentation, as it becomes harder for the attacker to pinpoint individuals, enhancing security.
A typical scenario might involve a healthcare institution aiming to share patient data without revealing sensitive personal details. By generalizing birth years and replacing specific diagnoses with broader disease categories, the data can be shared for broader research studies without easily compromising individual identities.
Generalization is considered a cost-effective approach as it doesn’t require complex algorithms or extensive computational resources. Instead, it simplifies data by replacing detailed values with broader categories. Therefore, the process is quite straightforward. Unlike some methods that distort data to preserve anonymity, generalization maintains the data’s integrity by representing it in a more aggregated form. This means the modified data closely preserves the original structure and meaningfulness of the data, ensuring that insights remain relevant while protecting individual specifics. It allows organizations to derive meaningful conclusions when sensitive information is not allowed to be exposed for compliance or legal concerns.
The Data Generalization technique is suitable for almost any data type, especially where trends are more critical than specifics. The method benefits analyzing large datasets, a considerable advantage point comprising it with other techniques.
However, there’s an inherent risk of data linkage, especially if generalized data is combined with other available data. Imagine a generalized dataset indicating people in their “30s” bought a specific car model. If an attacker knows John, aged 31, recently bought a car and cross-references this with another detailed dataset, they might infer John’s purchase choice from the generalized data. This violates John’s privacy, potentially revealing his preferences, habits, or other personal information that he expected would remain confidential when shared with the initial entity. This compromises the main objective of de-identification. This method of cross-referencing can potentially re-identify individuals, making it essential to carefully choose the generalization level to prevent unintended data linkage.
Hence, the risk is present but can be managed with careful consideration. Generalization works well when combined with other techniques such as Data Swapping. For instance, in the same example, we mention the car model, initially, John’s record might show “Ford, 2022” (original data), and then it changes to “Car, 2020s” (generalized). Swapping then might exchange John’s generalized data with another’s, making it “SUV, 2020s”. This dual-layered approach significantly obscures John’s specific purchase while retaining the dataset’s overall structure, enhancing security and making re-identification even harder.
Data Perturbation
Data Perturbation is a de-identification technique where original data values are modified slightly (small change), typically through the addition of random noise, making it unpredictable, to create a version of the data that looks and feels like the original but doesn’t exactly match it. The overall objective is to ensure that data remains statistically useful, while individual entries become harder to trace back to their sources.

Consider this example, Acme Corp, a leading pharmaceutical enterprise, recently developed a groundbreaking drug formula that could revolutionize diabetes treatment. Holding sensitive patient trial data, they decided to use Data Perturbation before sharing results with external research partners. The data consisted of individual patient metrics like age, weight, blood sugar levels, and responses to the drug. The objective was to protect patient identities and shield the proprietary formula details. The most significant risks were corporate espionage and patient re-identification. Threat agents ranged from rival pharmaceutical companies keen on reverse-engineering the drug formula to cybercriminals aiming to sell patient profiles on the dark web. By applying Data Perturbation, Acme Corp introduced minor randomized variations into the dataset. For example;
Age: 42 years -> 43 years.
Blood Sugar: 126 mg/dL -> 128 mg/dL.
Sensitivity Score: 7.5 -> 7.4.
These small changes effectively obfuscated individual patient profiles, making re-identification almost impossible, while preserving the overall statistical significance of the dataset. Additionally, the perturbed data prevented the exact replication of the formula. Thus, even if adversaries accessed the perturbed data, discerning the true essence of Acme’s innovative drug remained elusive, ensuring both business competitiveness and patient privacy.
Why does “Data Perturbation” opt for minor adjustments, like changing 42 years to 43 years, instead of more drastic changes such as 42 years to 62 years? Wouldn’t both approaches serve the same purpose?
Data Perturbation aims to maintain data’s statistical integrity while ensuring privacy. Minor adjustments preserve overall dataset trends and relationships, crucial for analysis. Drastic changes, like altering 42 to 62, could distort the data’s genuine patterns and reduce its utility, potentially leading to misleading conclusions or erroneous insights. Thus, minor perturbations strike a balance between privacy and data accuracy.
The main business case for using Data Perturbation over other de-identification techniques is when the exact original data values aren’t as crucial as the overall patterns and trends. Unlike techniques like generalization, which reduces the granularity of data, perturbation retains the data’s original granularity but slightly adjusts its accuracy.
Some notes to consider about Data Perturbation:
- Perturbed data maintains the statistical characteristics of the original, ensuring insights remain relevant.
- The process is algorithmic and can be applied quickly across large datasets.
- Once data has been perturbed, it’s nearly impossible to revert to its original state without the exact perturbation algorithm and parameters.
- After applying Data Perturbation, individual data points are not true representations, which might not be suitable for all analytical purposes. For example, data like sensor values, even changing it slightly, misleads calibration.
- If not done right, sophisticated adversaries might attempt to reverse-engineer the perturbation, especially if they have access to portions of the original data.
In summary, Data Perturbation is an ideal solution when maintaining statistical relationships in a dataset is essential, but individual data accuracy can be compromised slightly for the sake of privacy.
Hashing
Hashing is a method that converts any type of data as an input regardless of its size into a fixed-length string of bytes output without the possibility to reversely-engineer the process. Each time you hash the same input, will result in the same output. Hash values sometimes be referred to as the “Fingerprint” or “Signature” of the input data because in Hash there should be no single input that produces the same output unless the Hash function is vulnerable (known as hash collision).
Let us Hash some data:
Input Text: Hello
Output Hash (SHA1): f7ff9e8b7bb2e09b70935a5d785e0cc5d9d0abf0
Input Text: 12345
Output Hash (SHA1): 8cb2237d0679ca88db6464eac60da96345513964
Input Text: Abc123
Output Hash (SHA1): bec75d2e4e2acf4f4ab038144c0d862505e52d07
Note that Hashing is a case-sensitive process. This means that “Hello” and “hello” would produce different hash values:
Input Text: hello
Output Hash (SHA1): aaf4c61ddcc5e8a2dabede0f3b482cd9aea9434d
You don’t have to input only textual data, but could files, URLs, network packets, literally everything. The output will always be fixed in size and unique to the input data.
Regardless of the length of the input text, the Hash output value (SHA-1 in this example) will always be fixed in size (160 bits in SHA1).
There are multiple Hashing functions available each with different fixed output length, the most commonly seen:
Message Digest Algorithm 5 (MD5): Output Length is 128 bits
Secure Hash Algorithm 1 (SHA-1): Output Length is 160 bits
Secure Hash Algorithm 2 (SHA-2): The SHA-2 family has multiple variants, and their output lengths are;
SHA-224: 224 bits
SHA-256: 256 bits
SHA-384: 384 bits
SHA-512: 512 bits
SHA-512/224: 224 bits
SHA-512/256: 256 bits
Secure Hash Algorithm 3 (SHA-3): Like SHA-2, SHA-3 has multiple variants;
SHA3-224: 224 bits
SHA3-256: 256 bits
SHA3-384: 384 bits
SHA3-512: 512 bits
Most of you might recognize hashing from cryptography, where it’s often used to protect sensitive information, like passwords. when a user sets a password, the system will hash it and store the hash. When the user logs in, the system will hash the entered password and compare it to the stored hash. If they match, access is granted. The actual password is never stored, so even if attackers breach the database, they only find the hashes, not the original passwords.
Hashing, when it comes to de-identification, the usage of hashing can be a tad different, and it’s essential to understand its context. It serves to transform personally identifiable information (PII) into a non-human-readable format, much like it does for passwords. The idea is that even if someone gains access to the hashed data, they wouldn’t be able to ascertain the original information.
For example, imagine a medical dataset where patient names are hashed. John Doe’s name might become “ae6e4d1209f17b460503904fad297b31e9cf6362” a seemingly random string. Now, this dataset can be shared for Benchmarking, Drug Development, or any other purposes without revealing John’s identity directly. Researchers can still analyze data, like medical outcomes associated with each unique hash, but can’t directly associate findings with “John Doe.”
A good question would be, why would you use Hashing over Pseudonymization?
The key differences between using one over the other are:
Reversibility
Hashes are irreversible. But remember, the same input will yield the same hash, which can be a vulnerability.
However, in Pseudonymization, since the relationship between the original data and the pseudonym is maintained (usually in a separate lookup table), it’s reversible. This table needs strong protection.
Use Case
Hashing is the best fit for data that you don’t need to revert to its original form.
However, Pseudonymization is useful when there’s a potential future need to re-identify the data.
Getting back to our example:
Use Case 1: If patient details must remain confidential and non-reversible, hashing is the preferred technique. By hashing patient names or IDs, researchers can study patterns and trends without ever knowing individual identities. The irreversibility of a secure hash ensures patient privacy remains uncompromised.
Use Case 2: If the business requires occasional access to original patient details, pseudonymization is a better fit. While hashed values protect data, they’re irreversible. With pseudonymization, a separate secure lookup table can be used by authorized personnel to re-identify certain data, serving the auditing and business needs without compromising overall data privacy.
This might confuse you, but we emphasize to highlight it. Pseudonymization can utilize hashing as a method to generate pseudonyms instead of other ways. When we think of pseudonymization, we typically imagine replacing identifiable data with made-up names or codes. However, a hash function can serve this purpose as well, transforming original identifiers into consistent, unique hashed values.
However, while a hash can be used as a pseudonym, not all pseudonyms are hashes.
Encryption
Encryption is a method where data is transformed using a cryptographic algorithm into a form that’s unreadable without the corresponding decryption key. This has been a cornerstone in the data security and confidentiality.
In the context of de-identification, encryption is used to obscure specific pieces of data, ensuring that only those with the appropriate decryption key can access the real, underlying information. What sets encryption apart from other de-identification techniques is its reversibility. The original data can be fully restored, making it ideal for scenarios where data might need to be re-identified. However, this strength is also its potential weakness. If the decryption key is compromised, the original data can be exposed.
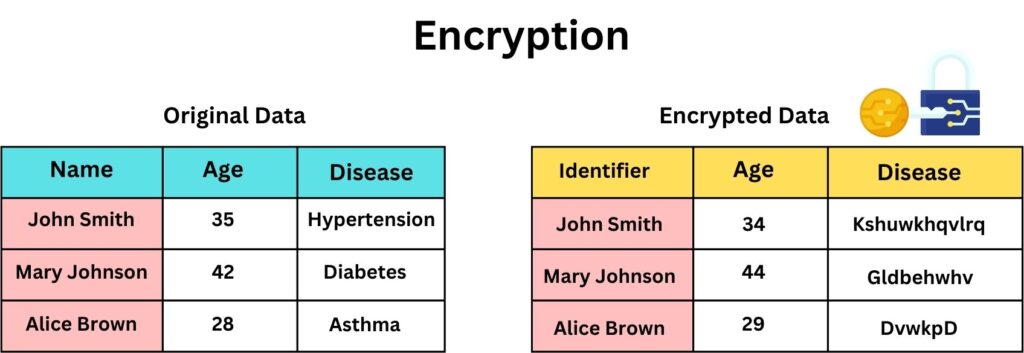
Consider a global bank that offers an app for its customers to conduct mobile banking. As customers travel, they might connect to various networks, from secure home WiFis to riskier public hotspots. The bank needs to ensure that transaction details, account numbers, and personal financial information are shielded from potential eavesdroppers. When a customer initiates a transaction, the bank’s app encrypts the data before transmission. Even if a cyber attacker intercepts this data mid-transmission, all they’d capture is an indecipherable mix of characters. The actual financial information, like account balances or transaction amounts, is securely protected. Only the bank’s secure servers, with the correct decryption key, can unlock and process this data. This encryption mechanism doesn’t just protect customer privacy but also builds trust. Customers are more likely to use the bank’s digital services, knowing their financial data is kept secure, irrespective of where they connect from.
Encryption’s effectiveness is tied to the strength of the cryptographic method used and the security of the decryption key. As cryptographic techniques advance, older encryption methods might become vulnerable, necessitating updates. This can introduce computational overhead, but the security benefits often outweigh the costs.
Many regulations like GDPR recognize encryption as an effective means to safeguard data, often providing exemptions or leniencies for encrypted data in the event of breaches.
Comparing De-Identification Techniques
This table provides a concise comparison of various de-identification techniques, highlighting their characteristics, benefits, and potential applications. It’s designed to offer a clear overview, helping you quickly figure out each method’s essence and understand the differences.
| Criteria | Pseudonymization | Tokenization | Data Swapping | Generalization | Data Perturbation | Hashing | Encryption |
|---|---|---|---|---|---|---|---|
| Methodology | Replaces sensitive data with artificial identifiers. | Substitutes data with unrelated tokens. | Exchanges specific data between records. | Reduces data precision. | Adds random noise to data. | Converts data to fixed-size strings. | Scrambles data which can be deciphered with a key. |
| Mechanisms | Assigning pseudonyms or fake identifiers. | Secure token vault and mapping mechanism. | Algorithmic or manual swap between dataset records. | Adjusting granularity, e.g., converting age 27 to 20-30. | Random data alterations within acceptable ranges. | Using hashing functions, e.g., SHA-256. | Employing encryption algorithms with keys. |
| Purpose | Maintain data utility without revealing real identities. | Protect sensitive data, especially in payment systems. | Disguise individual data for statistical analysis. | Broaden specific details to maintain user anonymity. | Obscure specific data points while retaining overall data patterns. | Render data unreadable and ensure data consistency. | Protect data confidentiality during storage or transmission. |
| Benefits | Data remains useful; privacy is enhanced. | High security for sensitive data; reduces data breach impact. | Good for large-scale statistical analysis; maintains aggregate data integrity. | Simplifies data; enhances privacy without extensive data modification. | Keeps overall trends; reduces data precision. | Data integrity checks; consistent and irreversible conversion. | Full data confidentiality; adaptable to various use cases. |
| Reversibility | Possible with mapping. | Possible with token vault. | Complex, but possible if exact parameters are known. | Partial; exact data is lost. | Partial to impossible; exact values are distorted. | Irreversible. | Reversible with the correct key. |
| Security Level | Moderate; depends on pseudonym generation and storage. | High; tokens reveal nothing about actual data. | Moderate; original data relationships are altered. | Moderate; reduces detail level. | Moderate; exact values are obscured. | High; irreversible transformation. | High; relies on encryption strength and key management. |
| Data Linkage | Moderate; if mapping is exposed. | Low; without token-data mapping. | Moderate to high; if swapping patterns are detected. | Low to moderate; granularity might still allow linkage. | Moderate; especially if original data patterns are known. | Low; unless hash collisions occur. | Low; unless encryption is broken or key is compromised. |
| Data Distortion Level | Low; only direct identifiers are changed. | Low; only specific data values are tokenized. | High; individual data points are shuffled. | Moderate; data is made less precise. | Moderate to high; random noise distorts actual values. | High; original data is completely transformed. | None; data is just scrambled but remains intact. |
| Acceptance (or how widely used): | Widely accepted; especially with GDPR. | Widely used in payment industry. | Common in census and large-scale studies. | Common in various industries. | Less common; specific use cases. | Very widely used; especially in IT. | Extremely common; core of most security protocols. |
| Integrity (comparing it with the original data) | High; only identifiers change. | High; only specific data points change. | Moderate to low; data is shuffled. | Moderate; data is approximated. | Moderate to low; noise affects original values. | Low; data is completely transformed. | High; original data is preserved but scrambled. |
| Data Example (Before and After) | Before: John Doe After: User12345 | Before: Credit Card Number: 1234-5678-9012-3456 After: Token: A1B2-C3D4-E5F6-G7H8 | Before: (John, $60,000, NY), (Jane, $90,000, LA) After: (John, $90,000, LA), (Jane, $60,000, NY) | Before: Age 27 After: Age 25-35 | Before: Salary $50,000 After: Salary $50,500 (with added noise) | Before: Password "Hello123" After: Hash "2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824" (SHA-256 example) | Before: Message "SecretData" After: Encrypted "J8f&2!sD#2" (This is a fictitious representation, actual encrypted data will be longer and more complex based on the encryption method used.) |
Quick Quiz
Case Study
Acme Corp stands as a testament to the world of multinational enterprises – vast, complex, and pulsating with data from multiple sources. Our Chief Information Security Officer (CISO) is faced with the challenging task of navigating the complex situation of Acme’s operational matrix while ensuring that data remains both secure and functional. Now, let’s journey alongside the CISO, digging into Acme’s challenges, piecing together solutions, and drawing insights from every decision made. How does our CISO cater to international data transfers while ensuring Acme remains compliant across jurisdictions? And how can data be harnessed effectively for research & analytics without compromising its integrity?
E-commerce Platforms and Cloud Migration
Imagine you’re a customer. You’ve just entered your credit card details on Acme’s platform. Would you feel at ease knowing your financial data might be exposed? This very concern drives our CISO towards Tokenization. By replacing sensitive details with unique symbols, the direct exposure of data is minimized. But there’s more – with an eye on Cloud Migration, encrypting transactional data becomes crucial. After all, transferring data to the cloud brings about potential vulnerabilities. Customers can shop with confidence, and Acme can expand its cloud-based infrastructure securely.
CRM Systems – Data Sharing and Regulatory Compliance
CRMs are the lifeblood of client-business interactions. They’re treasure troves of data. But with treasures come responsibilities. How do you share data for collaborative initiatives without risking privacy and exposure? Pseudonymization becomes our go-to. Names, when replaced with pseudonyms, enable teams to work with data without compromising individual identities. But remember the importance of international data transfers? Here, Encryption plays its role, ensuring that while data travels, it does so in a secure cloak.
HR Systems – Liability with Employee Trust
Imagine the aftermath of an HR data leak. The loss of trust, the potential lawsuits! Here, our CISO prioritizes Generalization. Instead of pinpointing an employee’s age, a range suffices. Now, data remains recognizable without direct reversibility, striking a balance. The outcome of such security would be employees feel more comfortable and gain trust.
Analytics & Big Data Platforms
Big Data is big responsibility. Acme’s reliance on data for insights demands that raw data remains untouched. But, is raw data safe data? This is where Data Swapping finds its place. By shuffling data points, individual profiling becomes a challenge, preserving privacy. And for broader categories, Generalization provides the overall view without the nitty-gritty details. Therefore, Acme’s analysts can draw patterns and insights without endangering individual data points.
Supply Chain Systems
Vendors, partners, contracts, the supply chain is indeed a complex web. How do you safeguard proprietary data? Hashing offers a protective shield, especially for vendor identifiers. It will transform recognizable data into non-recognizable strings when shared externally or when at rest, thereby reducing the risk of proprietary information leakage. The CISO decided to use Data Perturbation to protect sensitive supplier pricing and volume data. By introducing slight variations, he ensures third-party partners and internal teams only access approximated values, thereby safeguarding competitive trade secrets while still allowing effective operational planning and analysis.
This way, in Acme Corp, the security officer’s work shows how important it is to use data well and keep it safe. Every choice made teaches us how to mix business needs with security. As data becomes more and more important for business, we must keep it safe. Acme Corp’s story tells us this, and shows how we must always be careful and think of new ways to keep data secure.
Summary
In the increasingly cyber landscape, businesses continually grapple with the complex task of safeguarding sensitive information. This lesson explored and highlighted the domain of de-identification, an essential practice to protect personal and corporate data from unauthorized access, misuse, and breaches.
At its core, de-identification strips away identifiable markers from data, rendering it anonymous. This transformation is imperative, especially when handling Personal Identifiable Information (PII), Personal Health Information (PHI), intellectual properties, and business-sensitive records. The modern business environment, with its merging web of data sharing, third-party collaborations, cloud migrations, and regulatory obligations, amplifies the need for rigorous de-identification practices.
One might ask, why this fuss over data? The answer lies in the very essence of contemporary businesses. Data fuels decision-making, innovation, and customer relations. However, mishandled data not only leads to a breach of trust but also regulatory repercussions, tarnishing an organization’s reputation and incurring severe financial penalties. This is where our lesson’s initial emphasis on proactive data minimization becomes pertinent. Instead of always playing defense against potential threats, organizations are encouraged to actively minimize the exposure of sensitive data, Addressing risks before they escalate.
Each technique, as our in-depth exploration revealed, caters to distinct business needs. For instance, while tokenization fits seamlessly in payment gateways, generalization shines in market research.
In conclusion, in this era of data proliferation, the mastery of de-identification is not just an added skill but a necessity. Through a blend of theoretical understanding and practical insights, this lesson aims to empower businesses and individuals alike in their quest for robust data protection in today’s multifaceted business landscape.
Your Homework
- Explore the ethical implications of data de-identification. How does it impact consumer trust, and what are the potential risks if de-identification is improperly executed?
- Look into the healthcare sector. Identify scenarios where de-identification is crucial for patient data. How do hospitals and healthcare institutions ensure patient privacy while still enabling medical research?
- Explore the functionalities of a de-identification tools like ARX or other similar platforms. Share your experience in terms of user interface, ease of application, and effectiveness of the techniques provided.
- Research international data protection regulations, such as GDPR or CCPA. How do these regulations address de-identification? Write a brief comparing the approaches of at least two such regulations.
- Investigate the relationship between de-identification and data quality. How does each de-identification technique impact the quality and usability of the data for various purposes such as analytics, machine learning, and business decision-making?
If you learned something new today, help us to share it to reach others seeking knowledge.
If you have any queries or concerns, please drop them in the comment section below. We strive to respond promptly and address your questions.
Thank You